What's the difference between Monoliths, Microservices and Serverless, and when to use which
Posted | Reading time: 10 minutes and 39 seconds.

Contents
A blog post1 and their off-leading replies 2 3 has recently stirred conversations about monoliths vs microservices vs serverless. While a good discussion about software architecture is always a blessing, in that case, we have started by throwing together different buzzwords for the sake of the clicks. It is time to remember what Monoliths, Microservices and Serverless are. When to use which, and why you are not developing a monolithic application when you are integrated with many other teams working on the identical product via service endpoints and events.
But first, some classification.
What’s a monolithic application
A monolithic application, or Monolith, is a complete application that bundles all system components into a single executable. After the wave of Service-oriented architecture (short SOA) 4 around the beginning of the century, we failed to maintain the complexity of the created service landscapes and struggled with connectivity. The fact that maintaining the quality of an SOA is a tedious job 5 led us to go back to putting everything into one big executable - the Monolith 6, which is self-contained and usually has everything from User Interface and Data in one package.
A good example is a traditional confluence deployment 7. The application is packaged in a single WAR file and can be deployed into a Tomcat. The functionality of the entire package can just as quickly be verified, as most of the inter-package relations can be tested with Unittests and without much overhead. For this blog post, we will architect a similar simplified software, an intranet workspace where you can create, organise, search and collaborate on articles and files and comment on them.
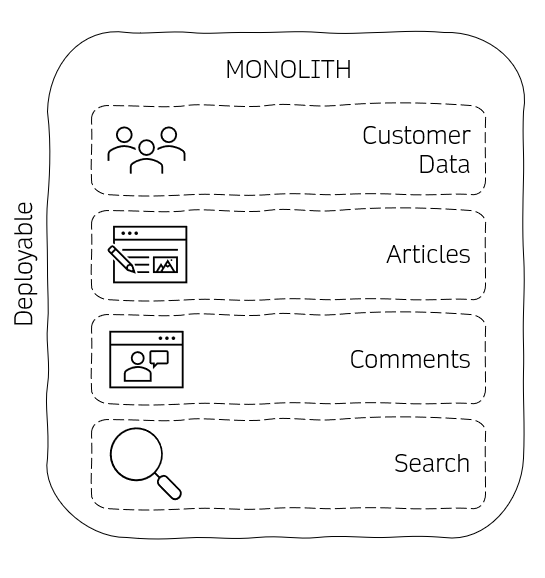
A monolithic architecture for an intranet workspace
As you can see, the simplicity of the deployment is convenient. However, suppose you are currently working in an environment where you need a platform team to manage the complexity of your infrastructure. In that case, you may wonder why we as an industry ever wanted to escape that. Yet we had good reasons to do so.
As our applications grew, so did our monoliths. While initially, you could run the WARs and DLLs on your development desktops (we didn’t use Laptops for development back then), in larger organisations, they quickly outgrew the capabilities of your machine. Thus, the advantage of having everything together promptly vanished. Also, as you always had the complete application running, triggering something as simple as the unit tests was a manoeuvre that could cost you multiple hours of your day. And while the deployment was more straightforward, the release was much more difficult. Various teams are bringing changes into the same executable, and this executable is doing everything; for every deployment, everything has to be tested and verified. If you have ever worked in an organisation with such a setup, you might know quarterly or yearly releases and job titles like Release Manager. The releases are not that infrequent because we wouldn’t want to release more often in such an environment. They are that unfrequent because verifying everything works, and no single added function in the Monolith cracks the performance. Because one tiny error in your change, one of a hundred or thousand changes that may be in a single release, can bring down the entire Monolith. And in production, you always have to ensure that the hardware you provide can handle the slowest part of the Monolith, even if 99% of it could run on a raspberry pi, making scaling hard and expensive.
As Head of Software, I measure my teams on multiple things. How often an organisation successfully releases to production and the amount of time it takes a code commit to get into production are two of them8. Suppose you are in a team of an organisation developing a monolithic application. In that case, those metrics are useless on a team level, as they will only be as good as the metrics from any other team. I’m measuring those things because I want to ensure that the teams can work independently. In a monolithic application, however, you are not independent. You can only deploy changes if you involve everybody else. One team that breaks the builds puts the entire organisation on hold.
Does that mean you should never do Monoliths? No, not at all. As Martin Fowler wrote on his blog 9, a monolith is perfect for starting your development. It can then play out its advantages, like simplicity, ease of testing and local deployments. And while your team is small, the disadvantages won’t come into play.
Microservices come into play only as your organisation diverges into separate teams with their own mission. In a small organisation, say, one or two teams, my metrics from above can still easily be tracked and provide insights into the team’s health. More so, as the teams are small and deployment is simple, the metrics are likely to be better for a team maintaining a monolith than multiple services, as many of the advantages that come with microservices, like faster decisions and more autonomy in an organisation, don’t apply to teams that run solo. They don’t have to manage the complexities that come with microservices.
Let’s sum up. Monoliths have some advantages, such as simplicity and ease of testing and deployment. Still, they also have many disadvantages as your application and organisation grow, such as slower release speed, scalability issues, and team coupling.
What’s a microservice application
Microservices are a software architecture pattern that builds complex applications from independent processes that communicate through language-agnostic interfaces 10. The services are loosely coupled and often built around a single bounded context 11.
As such, Microservices are an architectural and organisational approach to software development that allows the software to be composed of small independent services that communicate through well-defined APIs. Furthermore, these services belong to small, self-contained teams 12.
If we look at the overarching macro architecture for our system, the picture looks almost the same:

A microservice architecture for the intranet workspace
The major difference is that the different parts are independently deployable. While that looks like a small change, some string is attached when pursuing this type of architecture. This is because there is a significant difference between how the different services will interact and be deployed. The services can now be deployed independently, and the teams owning them don’t have to wait for others. But you will have to provide several core capabilities to ensure that the costs of this added distribution are not slowing you down. Examples of this are platform capabilities for deployment, often via containerisation 13, and testability of the different interfaces, for instance, via contract tests14. Issues that are common among distributed systems and that add complexity to the workload of the teams.
However, this additional complexity for teams in large organisations comes with many benefits. Teams can scale their modules independently without affecting other parts of the system, and they can use different frameworks, compute resources and architectures according to the best fit. This is exactly the benefits the team at Amazon could leverage on their decision to develop a more monolithic microservice. 1
But that doesn’t make their service a monolith. If it were, then the entire amazon prime would have to be packed in a monolithic application to fulfil the requirement because the amazon prime video application is much more than just the monitoring service. The monitoring service is, per definition, not a self-contained app, as it acts merely as a distributed addition to the application. Or, to visualise it slightly better, if you have a service landscape where out of 5 dots you suddenly make 1, you are still not building a monolithic application because all you did was create a right-sized service.
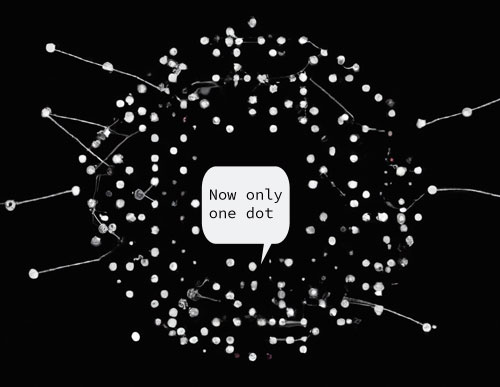
Reducing the number of dots in your macro architecture does not make your microservice landscape a monolith
It’s crucial to add that microservices are not the same as breaking all your functions into separate services, but as was so nicely described in Sam Newman’s book Building Microservices15, to allow you to separate the different bounded contexts of your application—a context like the audio/video monitoring.
Now where does the Monolith come into play in their article? Because compared to where they were before, their new microservice to them looks almost like a monolith. But before we go into the all-distributed case, let’s summarise microservices.
Microservices are modular software systems that offer benefits such as agility, scalability and autonomy to the teams while coming at the costs of higher operational complexity and requirements, for instance, in testing.
Serverless
The main difference between them is that microservices are long-running services that can perform multiple functions to fulfil everything that happens inside a bounded context. In contrast, serverless functions are short-lived and triggered by events. So serverless functions are a way to implement microservices, but not all are serverless. That sounds confusing? Well, bear with me for a second, and I hope I can make this more obvious.
As we said, Microservices allow us to decouple different bounded contexts from the general application. Looking at our architecture, you might already feel that Microservices are not as “micro” as their name suggests. And that’s true. It’s why I prefer to call them right-size-services earlier. Of course, microservices should not be made small for the sake of it, but only to the degree that they are small enough to ensure a low coupling in your overall application while maintaining a high cohesion.
That being said, many teams started to complain that microservices are no better than monoliths as it still takes quite a bit of work to get one up and to run, and having all the overhead of the spring boots, asp.net cores, Djangos, and friends didn’t feel as small as people hoped for especially if all they wanted to deploy was a single function.
So serverless functions helped teams deploy artefacts without caring about the infrastructure, provisioning, and scaling of their functions. It’s as easy as copying & pasting some text into a text box to get started. What has taken days to set up can be done in minutes now.
You will have to follow some pre-made decisions by your cloud provider, but it enables rapid prototyping and understanding your problem quickly. This approach was coined Serverless First 16, and it is seen as a starting point for developing your architecture forward. However, some argue for a Serverless-Only architecture, and an example could look like the following:
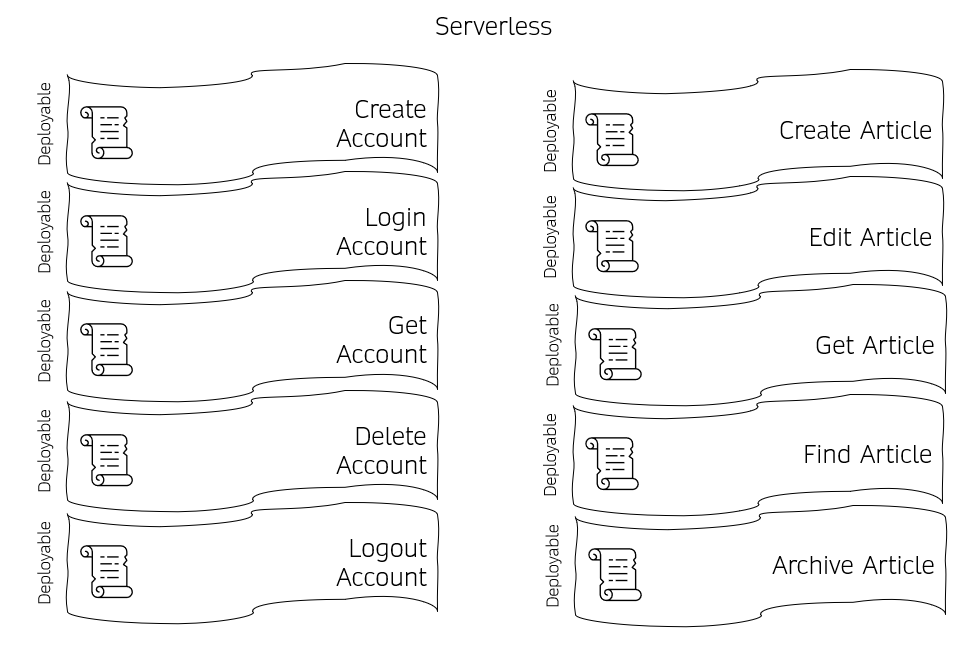
A serverless only architecture, with a few of the required serverless functions
The disadvantage here is that you will have to maintain a very distributed system and find a decent way to test this so you remember to simultaneously deploy changes in the account model to all the different functions.
When thinking about how to ensure low coupling and high cohesion in your architecture, you may struggle to maintain cohesion in such an architecture. It’s a valid starting point, though, and to come back to the Amazon team, it’s where they started. As they progressed, though, they discovered that they had a bounded context that needed a long-running, stable application, so the team refactored their serverless architecture into a microservice (not a monolith, as they claim). So it’s not a case against microservices, nor serverless, but a brilliant example of how to constantly challenge your architecture and ensure it develops into something better, preferably faster and cheaper.
To summarise, serverless functions are a lightweight way to deploy functionality rapidly, at the cost of increased complexity to maintain cohesion in your distributed system, but as a good starting point to iterate quickly and then develop into microservices or have some functionality not required to be running all the time.
Mixed Bag Architecture
Alright, we discussed many different architectures; which one to choose for you, then? First, a quick reality check. While we often get to see microservices as a perfect landscape with endless numbers of little services, in our example, it’s far more likely that the organisation would end up with something like this:
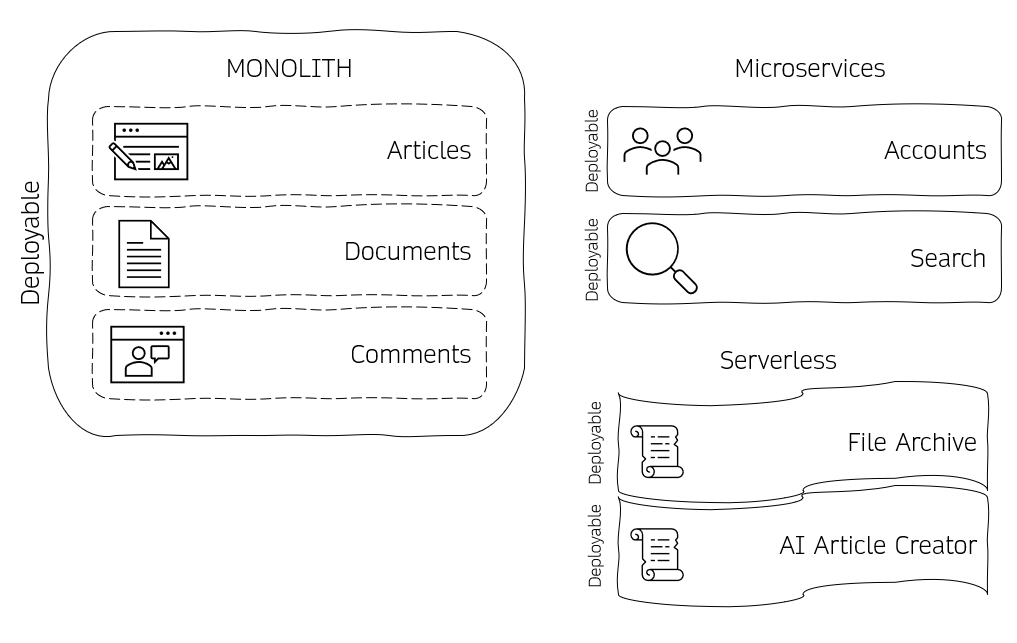
A mixed bag architecture
While some of the services have been moved out and taken over by different teams (in our example, that could have happened because the search got slow or a CRM drives the user management with a SaaS Authentication), most of the teams are still working on the original Monolith, which is still standalone but lacks some features, like the search. At the same time, it has multiple bounded contexts, is manageable in complexity and can be deployed quickly.
The costs of moving other parts out must be higher for the teams to take on the complexity of creating a further distributed system, but at some point, as their organisation grows, they might just come to that point. Additionally, the teams moved MVPs and little tasks running only occasionally with no requirements on quick startup time into serverless functions, mainly so they could forget about them.
In the end, there is no right or wrong guidance here. Whenever somebody tells you, “You always have to use Microservices”, “You always have to use Monoliths”, or “You always have to use Serverless”, they are automatically wrong because none of these statements is correct in their absoluteness. The perfect solution for you will always depend on your current situation, and the answer you find will change with time.
-
Scaling up the Prime Video audio/video monitoring service and reducing costs by 90% - primevideotech.com ↩︎ ↩︎
-
Even Amazon can’t make sense of serverless or microservices - linkedin.com ↩︎
-
Amazon Prime Video Just Went Back To Monolith - linkedin.com ↩︎
-
Building Confluence from source code - developer.atlassian.com ↩︎
-
Use Four Keys metrics like change failure rate to measure your DevOps performance - Google Cloud Blog ↩︎
-
Microservices - a definition of this new architectural term - martinfowler.com ↩︎
-
Bounded Context - Domain-Driven Design - martinfowler.com ↩︎
-
What Is Serverless-First in 2021? - Davind Anderson - thenewstack ↩︎